 |
|
|
|
|






PRINCIPI ELEMENTARI DI MISURAZIONE ELEMENTI DI INTERPRETAZIONE DELLE MISURAZIONI Usare strumenti di valutazione per misurare i problemi dei nostri pazienti ha senso solo se siamo capaci di dare un significato ai numeri assegnati alle variabili che vogliamo misurare ed ai punteggi che otteniamo con quelle misurazioni. Senza avere la pretesa di entrare nel merito della complessa problematica statistica, vogliamo ricordare brevemente, in questo capitolo, soltanto alcune nozioni relative ai punteggi ed ai confronti fra i punteggi, in modo da poter interpretare il risultato del nostro lavoro. Nel singolo soggetto, una variabile (generalmente indicata con la lettera x) (Tab.1.II) assume, in un determinato momento, un valore specifico (xi) fra tutti quelli ammissibili (x1, x2, ....xn); misurando quindi la stessa variabile in tempi diversi si potranno ottenere anche valori diversi. Le variabili che vengono impiegate più comunemente sono di due tipi, discrete e continue:
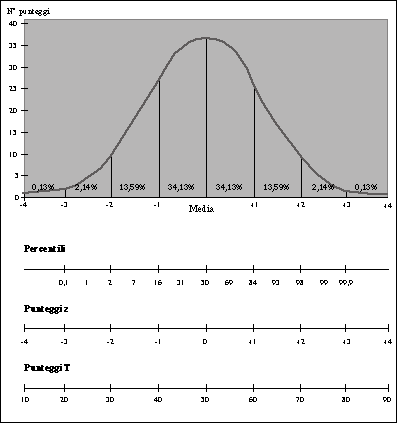
Tutti gli strumenti che noi usiamo (e non solo le RS) hanno una capacità di risoluzione più o meno limitata in funzione dell'unità di misura adottata, anche se, per convenzione, si accetta che questo non limiti, all'atto pratico, la possibilità di osservare ogni misura possibile. Poiché una misura ha un significato soltanto in rapporto ad altre, è necessario disporre di più di una misurazione della stessa variabile (p. es., valutazioni ripetute nel tempo di uno stesso soggetto o valutazione della stessa variabile in un gruppo di soggetti); l'insieme dei punteggi così ottenuti costituisce un campione (sample). Ogni campione è descritto dalla distribuzione che illustra la frequenza con cui compare ciascun valore di una data variabile (vedi Fig. 1.1). Per sintetizzare questi dati e renderli più comprensibili ed utilizzabili anche a fini di confronto si utilizzano le misure di tendenza centrale e quelle di dispersione che sono in grado di "riassumere" e rappresentare l'insieme di tutte le misure effettuate. La tendenza centrale è descritta da media, moda e mediana: - la media (M) corrisponde alla somma (·) di tutti i valori della variabile (x1, x2, x3... xn) divisa per il numero dei valori stessi (n), cioè delle osservazioni; - la moda è il punteggio che si osserva con maggiore frequenza; - la mediana è il punteggio che occupa la posizione centrale quando si ordinano i punteggi dal più basso al più alto. Quando media, moda e mediana hanno lo stesso valore si dice che la distribuzione è di tipo "normale". Gli indici di tendenza centrale ci dicono dove sono concentrati i valori della variabile; gli indici di dispersione ci dicono quanto i valori si disperdono intorno alle misure di tendenza centrale. Il concetto di dispersione dei valori di una variabile è inscindibilmente legato alla variabilità: se non ci fosse variabilità non ci sarebbe dispersione di valori. Sono misure di dispersione: il range, la varianza e la deviazione standard. Il range (o intervallo) è la differenza tra il punteggio più basso e quello più alto. La varianza è un indice che misura la tendenza dei punteggi a raggrupparsi intorno alla (o ad allontanarsi dalla) media dell'intera distribuzione. In termini matematici, la varianza è espressa dalla sommatoria (·) della differenza (elevata al quadrato) fra il punteggio di ciascuna osservazione (X) e la media del campione (M), divisa per il numero delle osservazioni (n) meno uno, secondo la formula: ·(X-M)2/(n-1) La radice quadrata della varianza è la deviazione standard (standard deviation - SD) che esprime la deviazione dalla media, cioè di quanto i punteggi di una variabile si discostano dalla media. La SD può indicare anche la percentuale dei punteggi più alti o più bassi rispetto ad un determinato valore: in presenza di una distribuzione normale, rappresentata graficamente dalla curva di Gauss (Fig. 1.1), una metà del campione presenta valori al di sopra della media e l'altra metà al di sotto; il 68.26% del campione presenta valori compresi fra la media ± una SD, il 95.45% fra la media ± 2SD ed il 99.73% fra la media ± 3SD. I punteggi che si ottengono con i vari strumenti di valutazione possono essere di diverso tipo o possono essere variamente elaborati; quelli che raccogliamo quando facciamo delle valutazioni sono i punteggi grezzi (raw scores), cioè la misurazione immediata, diretta, della variabile. Quando si usano più RS, i cui item abbiano un diverso range di punteggio, i punteggi grezzi sono di scarsa utilità perché non consentono un confronto fra le diverse scale (avrebbe poco senso, infatti, confrontare un punteggio di 35 di una scala che ha un range da zero a 60 con uno di 50 di un'altra scala con range da 30 a 100). È necessario, quindi, trasformare in qualche modo i punteggi grezzi per poterli rendere confrontabili tra loro. Una delle trasformazioni più comuni (anche se forse non è quella che dà più informazioni) è quella in percentili (percentile ranks) (Fig. 1.1): i percentili indicano la percentuale dei punteggi più bassi di un determinato punteggio grezzo. Con la trasformazione in percentili, la mediana rappresenta il 50º percentile (il 50% dei punteggi del campione è, cioè, al di sotto di quel valore); i punteggi che si collocano, rispettivamente, a - 3, - 2 e -1 SD corrispondono al 1°, al 2° ed al 16° percentile, quelli che si trovano a +1, +2 e +3 SD, corrispondono all'84°, al 98° ed al 99,9° percentile. Questo tipo di punteggi può essere utile quando si confrontano valutazioni effettuate su popolazioni o a intervalli di tempo differenti; così, ed esempio, conoscendo la distribuzione normale del quoziente di intelligenza (QI) in una determinata popolazione, si può stabilire in quale posizione si colloca il QI di un determinato soggetto rispetto a quella popolazione, a quale percentuale di essa, cioè, egli appartiene. Utilizzando strumenti di valutazione con unità di misura diverse, con questa tecnica si può vedere comparativamente l'andamento rispetto a ciascuno strumento
Fig. 1.1 - Distribuzione normale e punteggi standardizzati. Un confronto più diretto fra punteggi ottenuti con strumenti diversi si può comunque ottenere ricorrendo ai punteggi normalizzati o standardizzati (standard scores). I punteggi standardizzati di più comune impiego sono i punteggi z (z scores) ed i punteggi T (T scores) (Fig. 1.1). I punteggi z si calcolano portando a zero la media della distribuzione e facendo uguale ad 1 la SD; questi punteggi ci dicono, in sostanza, quanto il nostro punteggio si discosta dalla media. Con questa trasformazione i valori inferiori al punteggio medio danno numeri negativi, che possono essere fastidiosi da maneggiare nelle elaborazioni statistiche. Per non avere punteggi negativi si può ricorrere ai punteggi T (T scores) che hanno media arbitraria di 50 e SD di 10. I punteggi T sono impiegati in numerosi strumenti di valutazione quali, ad esempio, il Minnesota Multiphasic Personality Inventory - MMPI (1967) ed il Questionario per la Tipizzazione dell'Aggressività - QTA (1957). Come abbiamo già detto, un numero (e quindi anche il punteggio di una scala), per avere un significato, deve essere confrontato con altri numeri (o punteggi). Due sono i principali tipi di confronto, quello con un punteggio "normale" e quello con altre valutazioni dello stesso soggetto. Nel primo caso, si valuta di quanto il punteggio attuale si discosta da quello "normale", dal punteggio, cioè, idealmente rappresentativo della popolazione generale. L'impiego di strumenti che utilizzano questo tipo di confronto richiede spesso particolari cautele: è sempre opportuno accertarsi che gli strumenti siano stati testati su campioni sufficientemente rappresentativi, che il paziente faccia parte di quel tipo di popolazione (che, ad esempio, se il nostro paziente è un adolescente, lo strumento sia stato testato sugli adolescenti), che i dati "normali" siano abbastanza recenti, data la rapida evoluzione della società e delle sue norme socioculturali. Più semplice è il confronto con valutazioni precedenti del soggetto effettuate con lo stesso strumento. Questo sistema consente di valutare le variazioni del comportamento del soggetto nel corso del tempo, eventualmente in rapporto a specifici trattamenti, non richiede la trasformazione dei punteggi ed è sempre appropriato, essendo i punteggi utilizzati quelli del soggetto stesso e non di un campione che potrebbe essere non adeguato, non rilevante o cronologicamente non corrispondente. Quando è stata raccolta in maniera standardizzata una serie di valutazioni di campioni sufficientemente ampi di pazienti, è possibile sottoporre i dati raccolti a più complesse analisi statistiche che possono essere variamente finalizzate. Ma questo è un tema che esula dallo scopo di questo lavoro e che lasciamo ai numerosi trattati di statistica. |
TORNA ALL'INDICE GENERALE "SPECIALE SCALE DI VALUTAZIONE" POL.it è organizzata per rubriche e sezioni affidate a Redattori volontari che coordinano le varie parti della Rivista. Anche tu puoi divenare collaboratore fisso o saltuario della testata, scrivi utlizzando il link proposto sottto, dando la tua disponibilità in termini di tempo e di interessi, verrai immediatamente contattato. Come tante realtà sulla rete POL.it si basa sul lavoro cooperativo ed è sempre alla ricerca di nuovi collaboratori, certi come siamo che solo un allargamento della cerchia dei suoi redattori può garantire alla Rivista la sua continua crescita in termini di contenuti e qualità. ti aspettiamo..... |

![]()
![]()
